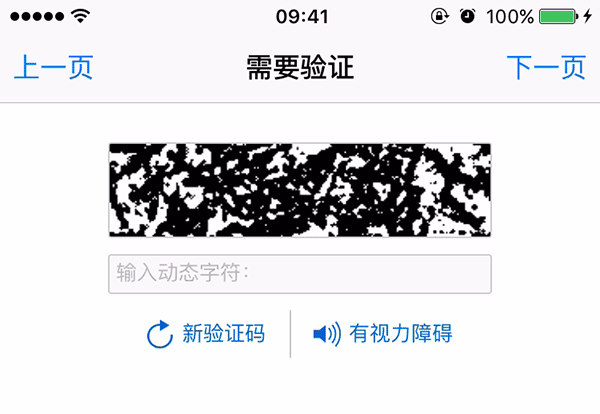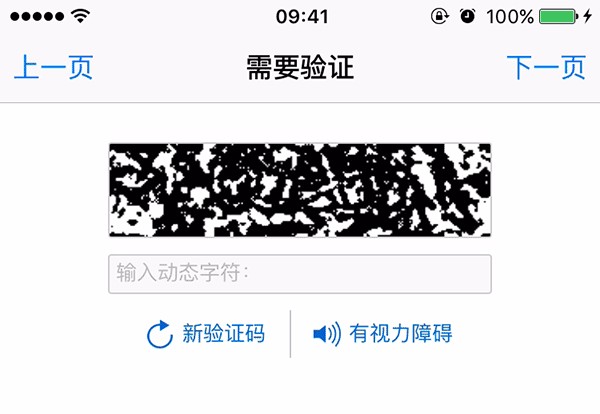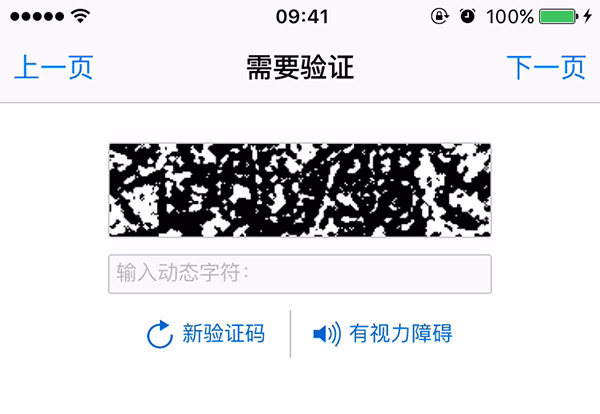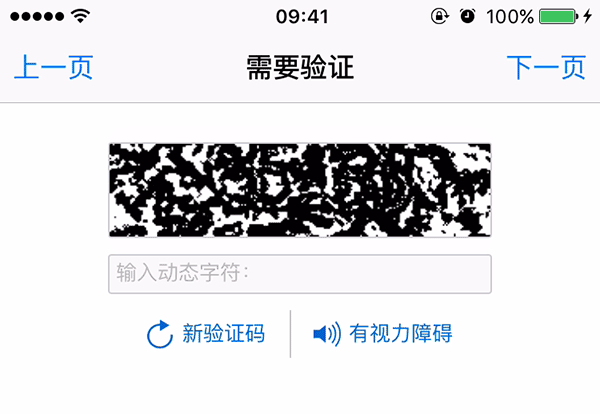
公司有一个业务需要抓取某网站数据,登录需要识别验证码,类似下面这种,这应该是很多网站使用的验证码类型。

首先由于验证码比较简单,图像不复杂,而且全部是数字。于是试着采用传统方式,按照网上教程自己简单改了一个,使用 PHP 识别。大概流程就是切割二值化去噪等预处理,然后用字符串数组形式保存起来,识别传来的图片同样预处理后比较字符串的相似度,选出一个相识度最高的分类。识别率不是很理想(验证码比较简单,应该能优化得更好),隐约记得只能超过60%。
因为识别效果不理想,目标网站登录状态还是能保持很久,没必要花太多精力在这上面,于是找了一个人工打码服务。简直太便宜了,一个月花不了多少钱,效果还好,只是有时候延迟比较高。反正对于我们的业务来说是足够用了。
机器学习大潮来临,我寻思着能不能用在这上面,于是参考 TensorFlow 识别手写数字教程,开始照猫画虎。
本文描述的只是作为一个普通开发者的一些粗浅理解,所有的代码和数据均在文后的 GitHub 有存留,建议结合代码阅读本文。如果有什么理解错误或 Bug 欢迎留言交流 ^_^
# TensorFlow 是什么
TensorFlow 是谷歌出的一款机器学习框架。看名字,TensorFlow 就是“张量流”。呃。。什么是张量呢?张量我的理解就是数据。张量有自己的形状,比如 0 阶张量是标量,1 阶是向量,2 阶是矩阵。。。所以在后文我们会看到在 TensorFlow 里面使用的量几乎都要定义其形状,因为它们都是张量。
我们可以把 TensorFlow 看作一个黑盒子,里面有一些架好的管道,喂给他一些“张量”,他吐出一些“张量”,吐出的东西就是我们需要的结果。
所以我们需要确定喂进去的是什么,吐出来的是什么,管道如何搭建。
更多的入门概念可以查看这个 keras新手指南 » 一些基本概念 (opens new window)
# 为什么使用 TensorFlow
没别的什么原因,只是因为谷歌大名,也没想更多。先撸起袖子干起来。如果为了快速成型,我建议可以看一下 Keras,号称为人类设计的机器学习框架,也就是用户体验友好,提供好几个机器学习框架更高层的接口。
# 大体流程
- 抓取验证码
- 给验证码打标签
- 图片预处理
- 保存数据集
- 构建模型训练
- 提取模型使用
# 抓取验证码
这个简单,随便什么方式,循环下载一大堆,这里不再赘述。我这里下载了 750 张验证码,用 500 张做训练,剩下 250 张验证模型效果。
# 给验证码打标签
这里的验证码有750张之巨,要是手工给每个验证码打标签,那一定累尿了。这时候就可以使用人工打码服务,用廉价劳动力帮我们做这件事。人工打码后把识别结果保存下来。这里的代码就不提供了,看你用哪家的验证码服务,相信聪明的你一定能解决 😃
# 图片预处理
- 图片信息: 此验证码是 68x23,JPG格式
- 二值化: 我确信这个验证码足够简单,在丢失图片的颜色信息后仍然能被很好的识别。并且可以降低模型复杂度,因此我们可以将图片二值化。即只有两个颜色,全黑或者全白。
- 切割验证码: 观察验证码,没有特别扭曲或者粘连,所以我们可以把验证码平均切割成4块,分别识别,这样图片识别模型就只需要处理10个分类(如果有字母那将是36个分类而已)由于验证码外面有一圈边框,所以顺带把边框也去掉了。
- 处理结果: 16x21,黑白2位
相关 Python 代码如下:
img = Image.open(file).convert('L') # 读取图片并灰度化
img = img.crop((2, 1, 66, 22)) # 裁掉边变成 64x21
# 分离数字
img1 = img.crop((0, 0, 16, 21))
img2 = img.crop((16, 0, 32, 21))
img3 = img.crop((32, 0, 48, 21))
img4 = img.crop((48, 0, 64, 21))
img1 = np.array(img1).flatten() # 扁平化,把二维弄成一维
img1 = list(map(lambda x: 1 if x <= 180 else 0, img1)) # 二值化
img2 = np.array(img2).flatten()
img2 = list(map(lambda x: 1 if x <= 180 else 0, img2))
img3 = np.array(img3).flatten()
img3 = list(map(lambda x: 1 if x <= 180 else 0, img3))
img4 = np.array(img4).flatten()
img4 = list(map(lambda x: 1 if x <= 180 else 0, img4))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 保存数据集
数据集有输入输入数据和标签数据,训练数据和测试数据。
因为数据量不大,简便起见,直接把数据存成python文件,供模型调用。就不保存为其他文件,然后用 pandas 什么的来读取了。
最终我们的输入模型的数据形状为 [[0,1,0,1,0,1,0,1...],[0,1,0,1,0,1,0,1...],...]
标签数据很特殊,本质上我们是对输入的数据进行分类,所以虽然标签应该是0到9的数字,但是这里我们使标签数据格式是 one-hot vectors [[1,0,0,0,0,0,0,0,0,0,0],...]
一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0**,比如[1,0,0,0,0,0,0,0,0,0] 代表1,[0,1,0,0,0,0,0,0,0,0]代表2.
更进一步,这里的 one-hot 向量其实代表着对应的数据分成这十类的概率。概率为1就是正确的分类。
相关 Python 代码如下:
# 保存输入数据
def px(prefix, img1, img2, img3, img4):
with open('./data/' + prefix + '_images.py', 'a+') as f:
print(img1, file=f, end=",\n")
print(img2, file=f, end=",\n")
print(img3, file=f, end=",\n")
print(img4, file=f, end=",\n")
# 保存标签数据
def py(prefix, code):
with open('./data/' + prefix + '_labels.py', 'a+') as f:
for x in range(4):
tmp = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
tmp[int(code[x])] = 1
print(tmp, file=f, end=",\n")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
经过上面两步,我们在就获得了训练和测试用的数据和标签数据,呐,就像这样
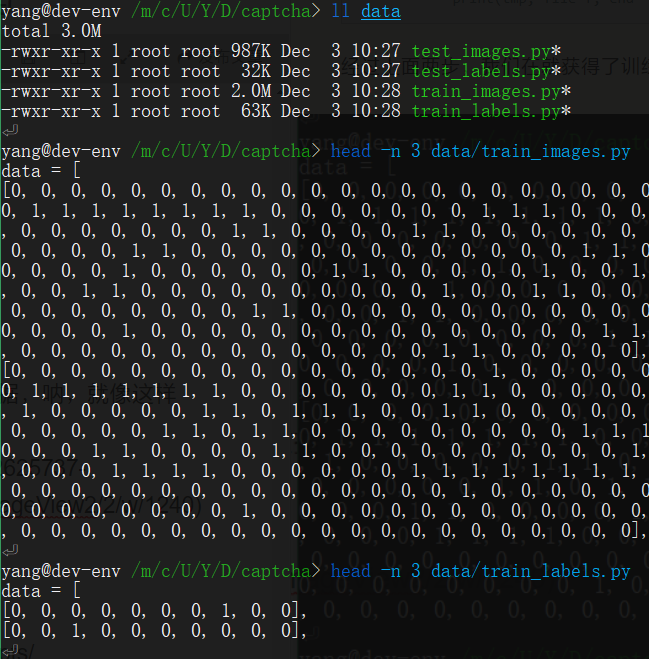
# 构建模型训练
数据准备好啦,到了要搭建“管道”的时候了。
也就是你需要告诉 TensorFlow:
# 1. 输入数据的形状是怎样的?
x = tf.placeholder(tf.float32, [None, DLEN])
None 表示不定义我们有多少训练数据,DLEN是 16*21,即一维化的图片的大小。
# 2. 输出数据的形状是怎样的?
y_ = tf.placeholder("float", [None, 10])
同样None 表示不定义我们有多少训练数据,10 就是标签数据的维度,即图片有 10 个分类。每个分类对应着一个概率,所以是浮点类型。
# 3. 输入数据,模型,标签数据怎样拟合?
W = tf.Variable(tf.zeros([DLEN, 10])) # 权重
b = tf.Variable(tf.zeros([10])) # 偏置
y = tf.nn.softmax(tf.matmul(x, W) + b)
2
3
4
是不是一个很简单的模型?大体就是
y = softmax(Wx+b)
其中 W 和 b 是 TensorFlow 中的变量,他们保存着模型在训练过程中的数据,需要定义出来。而我们模型训练的目的,也就是把 W 和 b 的值确定,使得这个式子可以更好的拟合数据。
softmax 是所谓的激活函数,把线性的结果转换成我们需要的样式,也就是分类概率的分布。
关于 softmax 之类更多解释请查看参考链接。
# 4. 怎样评估模型的好坏?
模型训练就是为了使模型输出结果和实际情况相差尽可能小。所以要定义评估方式。
这里用所谓的交叉熵来评估。
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
# 5. 怎样最小化误差?
现在 TensorFlow 已经知道了足够的信息,它要做的工作就是让模型的误差足够小,它会使出各种方法使上面定义的交叉熵 cross_entropy 变得尽可能小。
TensorFlow 内置了不少方式可以达到这个目的,不同方式有不同的特点和适用条件。在这里使用梯度下降法来实现这个目的。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# 训练准备
大家知道 Python 作为解释型语言,运行效率不能算是太好,而这种机器学习基本是需要大量计算力的场合。TensorFlow 在底层是用 C++ 写就,在 Python 端只是一个操作端口,所有的计算都要交给底层处理。这自然就引出了会话的概念,底层和调用层需要通信。也正是这个特点,TensorFlow 支持很多其他语言接入,如 Java, C,而不仅仅是 Python。
和底层通信是通过会话完成的。我们可以通过一行代码来启动会话:
sess = tf.Session()
# 代码...
sess.close()
2
3
别忘了在使用完后关闭会话。当然你也可以使用 Python 的 with 语句来自动管理。
在 TensorFlow 中,变量都是需要在会话启动之后初始化才能使用。
sess.run(tf.global_variables_initializer())
# 开始训练
for i in range(DNUM):
batch_xs = [train_images.data[i]]
batch_ys = [train_labels.data[i]]
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
2
3
4
我们把模型和训练数据交给会话,底层就自动帮我们处理啦。
我们可以一次传入任意数量数据给模型(上面设置None的作用),为了训练效果,可以适当调节每一批次训练的数据。甚至于有时候还要随机选择数据以获得更好的训练效果。在这里我们就一条一条训练了,反正最后效果还可以。要了解更多可以查看参考链接。
# 检验训练结果
这里我们的测试数据就要派上用场了
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(sess.run(accuracy, feed_dict={x: test_images.data, y_: test_labels.data}))
2
3
我们模型输出是一个数组,里面存着每个分类的概率,所以我们要拿出概率最大的分类和测试标签比较。看在这 250 条测试数据里面,正确率是多少。当然这些也是定义完操作步骤,交给会话来运行处理的。
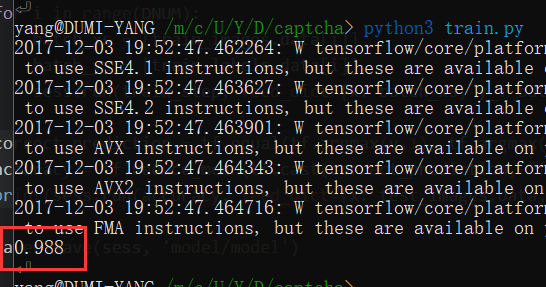
# 提取模型使用
在上面我们已经把模型训练好了,而且效果还不错哦,近 99% 的正确率,或许比人工打码还高一些呢(获取测试数据时候常常返回有错误的值)。但是问题来了,我现在要把这个模型用于生产怎么办,总不可能每次都训练一次吧。在这里,我们就要使用到 TensorFlow 的模型保存和载入功能了。
# 保存模型
先在模型训练的时候保存模型,定义一个 saver,然后直接把会话保存到一个目录就好了。
saver = tf.train.Saver()
# 训练代码
# ...
saver.save(sess, 'model/model')
sess.close()
2
3
4
5
当然这里的 saver 也有不少配置,比如保存最近多少批次的训练结果之类,可以自行查资料。
# 恢复模型
同样恢复模型也很简单
saver.restore(sess, "model/model")
当然你还是需要定义好模型,才能恢复。我的理解是这里模型保存的是训练过程中各个变量的值,权重偏置什么的,所以结构架子还是要事先搭好才行。

# 最后
这里只是展示了使用 TensorFlow 识别简单的验证码,效果还不错,上机器学习应该也不算是杀鸡用牛刀。毕竟模型无脑,节省很多时间。如果需要识别更加扭曲,更加变态的验证码,或许需要上卷积神经网络之类,图片结构和颜色信息都不能丢掉了。另一方面,做网站安全这块,纯粹的图形验证码恐怕不能作为判断是不是机器人的依据。对抗到最后,就变成这样的变态验证码哈哈哈。